流水账:Suse下安装Storm-单机和集群模式
03 Apr 2014
#1. 安装单机版
Storm的依赖软件比较多,需要装Python、zookeeper、zeromq以及jzmq,然后才是storm的安装。
###1.1 安装Python2.7.x
- 编译安装过程略
###1.2 安装jdk 1.6.x
- 解压tar包即可使用,更高版本的jdk未测试,应该也可以。
以下bashrc中的java,zookeeper等bin路径均用ln -s做了软链,主路径不再带版本号,如下:

- 在~/.bashrc中追加:
export JAVA_HOME=”/home/arvinpeng/proj/jdk”
export PATH=$JAVA_HOME/bin:$PATH:/sbin - 然后执行source命令
source ~/.bashrc
###1.3 安装Zookeeper3.4.6
- 解压tar包即可使用,更高的版本应该也兼容
- 在~/.bashrc追加:
export ZK_HOME=”/home/arvinpeng/proj/zookeeper”
export PATH=$JAVA_HOME/bin:$ZK_HOME/bin:$PATH:/sbin - cp zookeeper/conf/zoo_sample.cfg zookeeper/conf/zoo.cfg (用zoo_sample.cfg制作$ZK_HOME/conf/zoo.cfg)
###1.4 安装ZeroMQ-3.2.4
- 编译安装过程略
- 执行ldconfig命令刷新动态装入程序(ld.so)所需的连接和缓存文件(缓存文件默认为/etc/ld.so.cache)
sudo ldconfig
###1.5 安装jzmq
注意要在zmq之后安装,jzmq依赖zmq。
- 下载jzmq-master.zip,https://github.com/zeromq/jzmq
- unzip jzmq-master.zip
- cd jzmq-master
./autogen.sh(此脚本中调用了autoreconf命令,如果找不到这个命令,使用which命令查看一下命令路径,可能和$PATH中的不一致,给augogen.sh中的autoreconf加上绝对路径即可) - ./configure
- make
- make install
###1.6 安装配置Storm 墙裂建议安装不低于0.8.2版本的storm,我当时装了0.8.1,结果打包storm-starter测试代码时报错: import backtype.storm.task.IMetricsContext找不到,换成0.8.2即可。
- 安装过程略,解压即用。
- 在~/.bashrc追加:
export STORM_HOME=”/home/arvinpeng/proj/storm”
export PATH=$JAVA_HOME/bin:$ZK_HOME/bin:$MAVEN_HOME/bin:$STORM_HOME/bin:$PATH:/sbin
到此为止单机版的Storm就安装完毕了。
###1.7 测试一下本地模式的WordCount
Github里有一个例子叫做storm_starter,我们可以用它来做测试。
我们用eclipse打包后进行上传。
注意,我的storm安装在命令行linux下,打包是在windows的eclipse里进行。
- 安装twitter4j-4.0.1
unzip twitter4j-4.0.1.zip - 追加源文件storm-start/src/jvm/storm
使用eclipse建立java project。追加twitter4j和storm的jar文件。
File-> New -> Java Project ->StormHelloworld-> Next -> Libraries -> add External JARs…-> 追加twitter4j和storm的jar文件(/path/to/twitter4j/lib/*.jar和/path/to/storm/lib/*.jar和/path/to/storm/storm-{version}.jar)-> Finsh -
导入storm-start
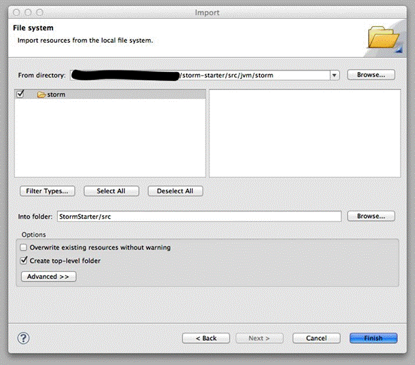
File -> Import -> General -> File System -> Next -> Browse(From directory) -> /path/to/storm-start/src/jvm/storm -> Browse(Info floder) -> xxx -> src -> OK -> “storm” 和 “Create top-level folder”前打勾 -> Finish
完成之后如图(用网上的图,都一样,参考下即可):
- 追加源文件storm-start/multilang/resources×(python 文件word count用)
File -> Import -> General -> File System -> Next -> Browse(From directory) -> /path/to/storm-start/multilang/resources -> Browse(Info floder) -> xxx -> OK -> check “resources” and “Create top-level folder” -> Finish
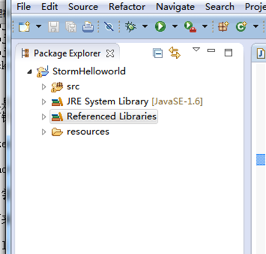
2个源文件都追加好之后,eclipse左边显示如下图:
此时我的eclipse里报语法错,有个CircularFifoBuffer类找不到:
org.apache.commons.collections.buffer.CircularFifoBuffer
这个类在commons.collections-{version}.jar里,搜索一下下载下来导入到项目里即可。我用的版本是:commons.collections-3.2.1.jar
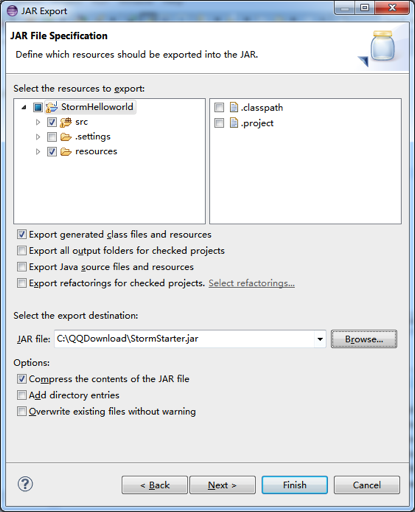
- JAR export
File -> Export -> JAR -> JAR file -> 取消 “.classpath” ,“.project” 和 “<.settings” ->的勾 browse -> path/to/export/name.jar -> Finish (忽视 warnings)
打包时碰到一堆warning:
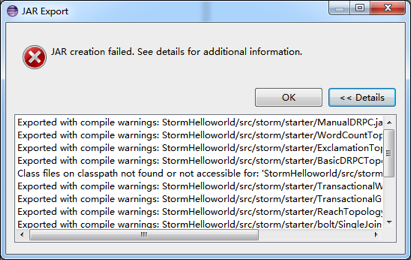
忽略即可。
- 执行刚才编译的文件,建议把输出重定向到文件,方便查看输出log。
storm jar StormStarter.jar storm.starter.ExclamationTopology > run.log
如果出现类似下面的文字,说明运行成功!
….
11367 [Thread-25] INFO backtype.storm.daemon.task - Emitting: class storm.starter.ExclamationTopology$ExclamationBolt
source: 2:3, stream: 1, id: {}, [golda!!!]
….
附截图:
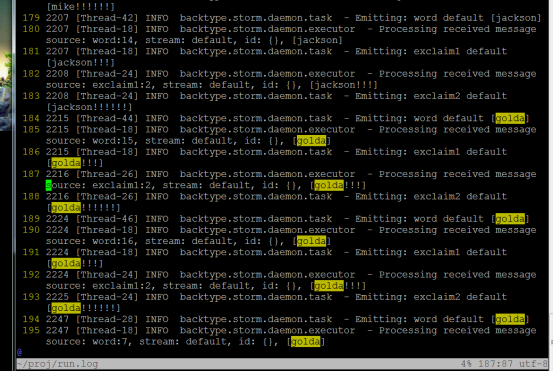
#2. 安装集群版
首先说一下我的袖珍小集群,总共有2台机器:strom_nimbus,storm_supervisor1。
###2.1 在集群上的每台机器上更新/etc/hosts文件
加入:
10.1.152.80 storm_supervisor1
10.1.152.119 storm_nimbus
###2.2 首先按照单机安装模式把集群中每台机器的环境都装好,然后我们开始进行配置
###2.3 配置zookeeper
由于zookeeper的算法是要求单数台机器完成,所以在配置的时候必须注意zookeeper要配置单数台机器,配置偶数台机器会出现一些无法预知的错误。在这2台机器中,我们选择storm_nimbus安装zookeeper(按照1.3)。
接下来配置zookeeper(注意这里是重点):
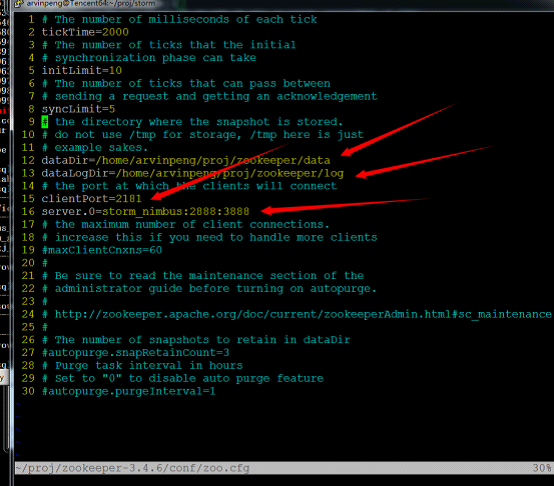
其中标红的就是需要修改的地方。
创建 dataDir和dataLogDir目录,并在dataDir目录下执行:
echo x > myid
这一步是每台电脑上都不同的。具体x参见zoo.cfg中server.x=hostname:portNumber:portNumber的x。也就是说在我的配置文件中,storm_nimbus是0。
在strom_nimbus上启动zookeeper:
zkServer.sh start
接下去有几个命令是查看集群中zookeeper状态的:
echo ”stat“ | nc HOSTMASTER 2181
echo ”conf“ | nc HOSTMASTER 2181
echo ”dump“ | nc HOSTMASTER 2181
echo ”wchs“ | nc HOSTMASTER 2181
echo ”ruok“ | nc HOSTMASTER 2181
bin/zkCli.sh.stat /
bin/zkCli.sh ls /
然后创建zookeeper临时文件。
sudo mkdir /tmp/zookeeper
sudo mkdir /var/log/zookeeper
好的,zookeeper的集群安装已经完成了。
这时候查看一下dataDir和dataLogDir目录,应该有一些新生成的目录。
###2.4 配置storm
storm的配置文件是storm.yaml,每台机器配置成一样。
这个脚本文件写的不咋地,所以在配置时一定注意在每一项的开始时要加空格,冒号后也必须要加空格,否则storm就不认识这个配置文件了,切记。
接下来,我们来看一下这个配置文件怎么配置,同样,标红的就是需要修改的地方。
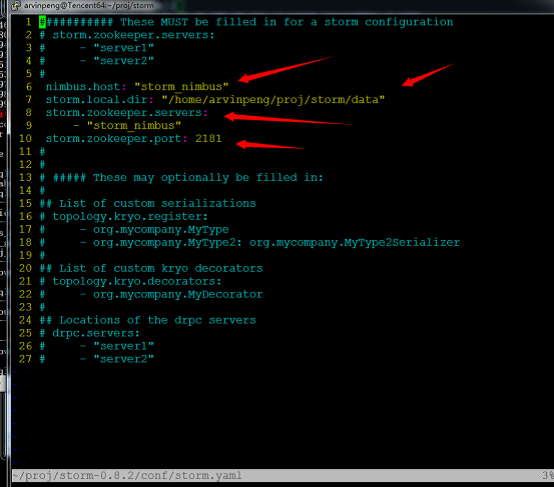
说明一下:storm.local.dir表示storm需要用到的本地目录。nimbus.host表示那一台机器是master机器,即nimbus。storm.zookeeper.servers表示哪几台机器是zookeeper服务器。storm.zookeeper.port表示zookeeper的端口号,这里一定要与zookeeper配置的端口号一致,否则会出现通信错误,切记切记。当然你也可以配superevisor.slot.port,supervisor.slots.ports表示supervisor节点的槽数,就是最多能跑几个worker进程(每个sprout或bolt默认只启动一个worker,但是可以通过conf修改成多个)。
至此,我们的storm集群就配置好了。
接下来我们测试一下,依然用我们打包好的StormStarter.jar。通过阅读源码我们可以知道,WordCountTopology在编写的时候如果在命令后不加参数,则是一个本地模式的WordCount,而如果有一个参数,也就是集群上的计算拓扑(Topology)名,它就会是一个在集群上跑的计算拓扑。
我们使用storm nimbus &(主节点)和storm supervisor &(从节点)启动storm。启动完毕去看一眼storm.local.dir目录,会有新的文件和目录生成。
storm还提供了一个可视化的工具,我们通过在主节点上输入命令# bin/storm ui来启动它,然后我们就可以在http://{NimbusHost}:8080进行查看。
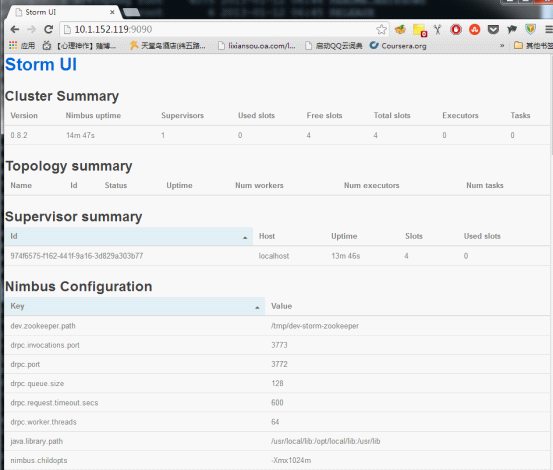
我这里修改了storm UI默认的8080端口,修改方式是直接在storm.yaml中增加一行:
ui.port: 9090
更多storm配置修改,参考Storm配置项详解。
那我们跑一下WordCount:
storm jar StormStarter.jar storm.starter.WordCountTopology WordCount_1
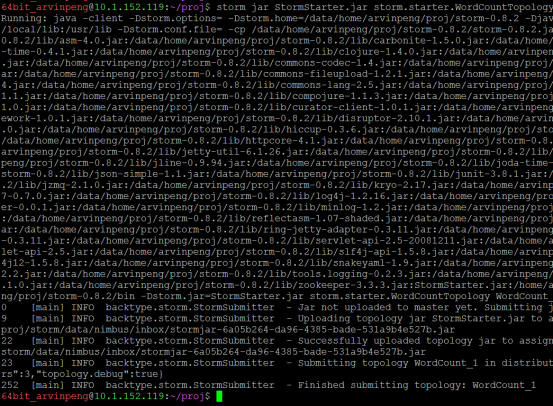
如上,启动成功。
查看一下ui,如果可以在ui中监视到,表明启动成功,从此我们的WordCount_1就正常地跑起来了,这个就是传说中的topology。
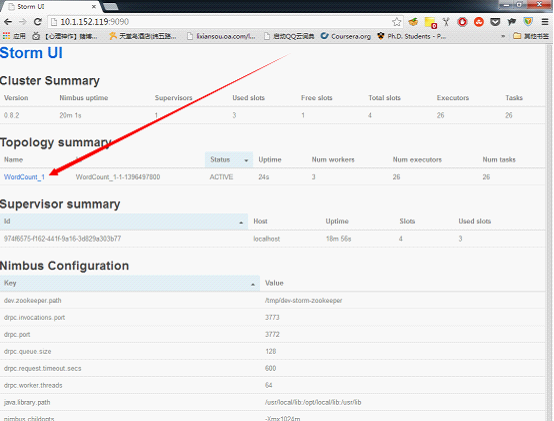
如果想杀死这个topology,运行以下命令:
storm kill WordCount_1