机器学习实践:被嗶哩嗶哩抛弃的人
30 Nov 2013
###背景&相关知识点
嗶哩嗶哩以弹幕和动漫闻名于宅男界,俗称B站。宅男会员们纷纷表示有了弹幕,看动漫再也不孤单O.O
B站的另一特色是神秘的会员制,要想成为会员,首先要回答上百道涵盖动漫,计算机,人文地理等相关领域学科知识的题目,只有达到一定分数线才能注册成为会员。成为会员后(一种好优越的感觉),有个会员专属的神秘世界等你挖掘。今天的主角,是那些由于乱发弹幕被B站拉入黑名单的会员同学,我们试图从他们身上发现些什么….这就引出本次话题:机器学习实践新番,寻找独立特征!
寻找独立特征类似于聚类,属于无监督学习算法。算法核心是非负矩阵因式分解(NonNegative Matrix Factorization),即对于矩阵V,它的所有元素均为非负值,通过特定的方法对其进行因式分解(V = A * B,其中假设V是m*n的矩阵,则A是m*r的矩阵,B是r*n的矩阵,且r小于m和n中的较小值),从而达到降维的目的,此方法在图像处理中应用广泛。在机器学习里面,可以使用NMF对数据进行特征提取,请允许我以本次的内容举个例子:

就用稍后我们拿到B站的黑名单数据(这个页面源码下下来竟然有30M之巨,O了个rz的)来说吧,然后经过简单处理会得到一个矩阵V,其中第一列为用户名,其余列为所有用户弹幕评论的用词(经过分词后的)。V[i][j]表示第i个用户弹幕评论里出现了V[i][j]次第j个词语。假设黑名单里有n个用户,所有用户评论的分词总个数为m,那么V的维度为n * m。这必然会是一个极其稀疏的矩阵啊,来,搂一眼局部地区:
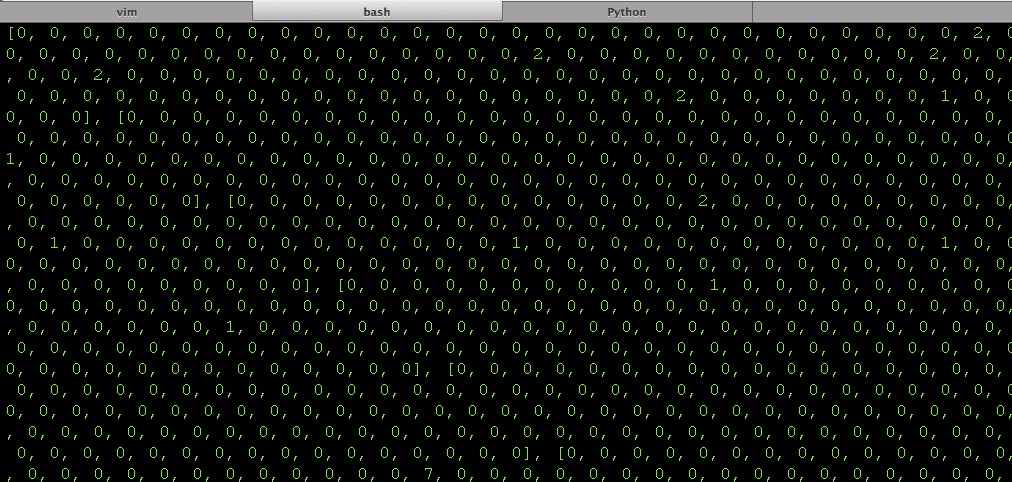
…

NMF对矩阵分解的具体做法是:假设原始矩阵为V,其中V[i][j]表示第i个用户在弹幕中使用了V[i][j]次第j个词语,我们把V分解为W * H,其中W是权重矩阵,H是特征矩阵。W的行为用户,列为各个特征,W[i][j]表示对特征j对用户i贡献的权重。H的行为特征,列为各个词语对当前行特征的重要度,H[i][j]表示单词j对特征i的重要程度。手动在纸上比划一下,你会发现把W和H做矩阵相乘,得出的矩阵和原始矩阵V的意义是相同的,amazing
以上便是NMF的神奇原理,而怎么又快又好的实现非负矩阵分解的过程(NP问题),便是下面说的MUR要做的事情了。
NMF的方法有很多,今天介绍一种收敛效果和运算效率平衡性相对较好的一种算法:乘法更新法则(Multiplicative Update Rules)。算法流程参考原始论文或者《集体智慧编程》第10章。这里吐个槽,我在使用MUR算法原始版跑B站数据时,MUR迭代一个循环就异常退出了,原因是非负矩阵中有0项,而MUR更新因子矩阵过程中出现了矩阵相除的步骤,于是程序遇到除0的异常。原始论文和书里并没有提到这个问题,我开始临时把矩阵所有元素都初始化为1(原始应该为0),后来上网搜索相关文献,终于找到另外一篇论文也在吐槽这个问题,并给了解决方法,即把除法的分子分母都加上一个正数,避免除0,属于拉普拉斯平滑的思想。跟我的方法类似,都是给分母加上一个正因子避免分母为0。然,不幸的是我采用论文里提到的方式进行测试时,发现MUR竟然不能收敛,迭代到最后差值始终在一个范围内小幅波动,不完美啊!于是我调整为只对分母加正因子的方法,经过测试可以收敛到一个局部最小点。
背景知识点就不继续展开了,本次算法在《集体智慧编程》第10章有详述。
###数据收集(注意,下面多图,如果看不清请直接右键新标签页打开观看)
由于黑名单就一个页面,所以直接手工把源码拖下来然后用beautifulsoup渲染一下提出我们需要的数据即可。数据是2013年11月24号的黑名单,这个黑名单好像一直在动态变化的说。数据提取完,总共有600多位同志中枪,数据如下,你们感受一下。
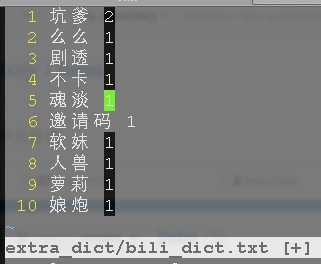
分词用的是结巴分词,注意结巴分词会把特殊字符过滤掉变成空格,而这批被封的无良会员发的奇葩评论各种奇怪字符, 需要去改一下分词的代码,把你想保留的词加到分词的正则式里, 这里我把*保留了下来。除此之外还需要我们加入自定义的分词词典,因为这是被封的弹幕,各种新新词语你懂的,下图是我的自定义词典,第二列为词频,你大概能猜到这帮娃的品味:
分词完毕,我们分别统计各个会员使用的某个词语的次数,和所有词语被所有会员使用的次数以及会员数,通过这些数据构造我们的原始矩阵usr_comment_m,行为用户,列为某个词语被当前用户使用的次数,没有使用过次数为0。
###特征的选取
特征数量决定了特征矩阵和权重矩阵的维度,也就是上面说的r。如果你也跟我刚开始一样天真的以为被禁的弹幕只有反动,色情,辱骂,恶意刷屏这么简单,我只能说这是理想情况,只假设有5,6个特征来进行矩阵分解时,会发现效果很不好。因为所有被封的弹幕评论里被一小撮高频词语占据,比如下面这种臆想症患者类型:

以及下面这种充满了怨念的类型:


上面这种类型的弹幕有力的提高了特定词语的出镜率,对我们的正常作业干扰很大。
所以特征选取太少的话你会发现特征都一样(如果我们用特征矩阵中特征对应的top X的特征词来表示这个特征)。另一方面由于用户基数太少,单用上述几个特征不能很好体现出区分度,长尾评论的个性化程度很大。无法归到上述某个特征里,经过一番痛彻心扉的调整,最后特征数暂且定为25。ok, 一切就绪,套上数据测试。
###结果解读
由于特征矩阵和权值矩阵规模太大不适宜直接观看,我们把最接近每个特征的前10个用户和这个用户与当前特征匹配的权重打印出来,结果在features.txt里,再把每个用户对应的top 3的特征和这个特征与当前用户匹配的权重打印出来,放到user_feature.txt里。这里特征就用特征矩阵里对当前特征贡献度排名top 10的关键词来代表。
首先是features.txt, 如下是第1条特征的数据:
#0:飞,黑子,非战斗,非战,非,阿,银,都,那个,那, 奶奶嘴酱 17.5245169749 天国の节操君。 0.0267150772494 幽灵残月 0.00466416868278 雨丶前尘梦 0.00463158785659 我就是⑨】 0.0024635743564 Peerless_W 0.00111117279873 aberSakur 0.000771241002643 SC2中的艾吉奥 3.65137888828e-05 chouzige 2.92005252477e-05 きのこ菌 1.50597758399e-08
其中“飞”对第一条规则影响最大,所以上述用户的评论中应该或多或少都出现了”飞”或者“黑子”,让我们把目光转向源数据,看一看排名前几位的用户到底发了啥:


再来看一下第7条特征:
#6:**,*,飞,lt,是,都,你,不知,黑子,非战斗, 林离 2.2628186348 ldhxldh 2.26229691825 下限帝四面 2.26229691792 魂魄.灵梦 1.46666176686 亾时无罓诳语 1.46521541398 奶奶嘴酱 0.670316097798 .bilibili. 0.039376337286 安若茜 0.00738172222572 renzaohaji 0.00328307286697 无爱吐槽君 0.00283976841048
可见”*“和”**“起了很大作用,看看排名前几位的同学做了啥:




不做评论鸟。。。
然后再看一下user_feature.txt的数据,这个数据顺序是和我们的原始数据保持一致的,即每个用户一行且顺序和原始数据保持一致:
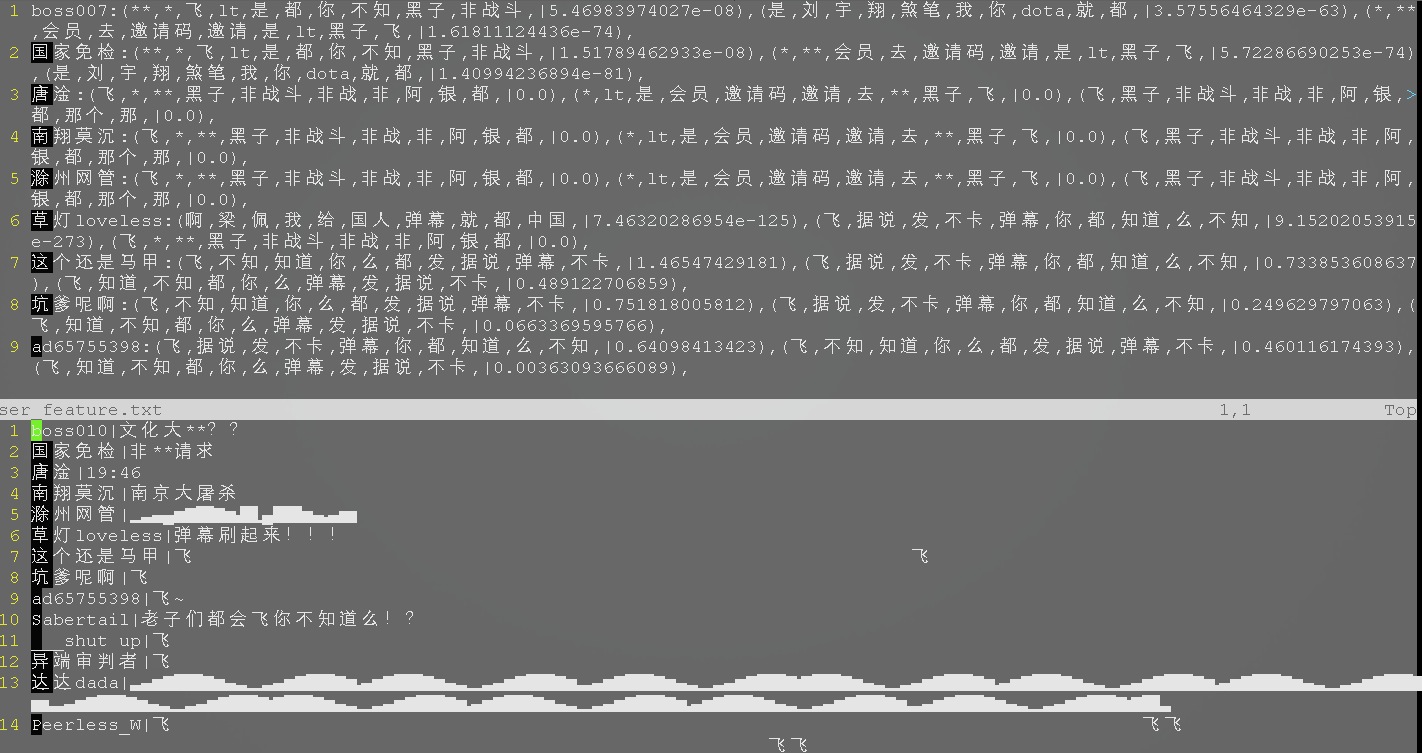
如果图小请右键新标签页打开观看。第一位用户和他关联度最高的规则是”**“打头的,关联度权值为5.46983974027e-08,用户评论中出现了”**“,但是悲剧的是在分词和转码的过程中第一位用户的名字被篡改了,可无视。第三位用户没有规则和他关联,因为弹幕太特殊了。第六位用户评论高中出现了“弹幕”,所以“弹幕”的规则关联权值较高。我们单独寻找一下“奶奶嘴酱”这位用户的规则分类情况:
奶奶嘴酱:(飞,不知,知道,你,么,都,发,据说,弹幕,不卡,|113.02213089),(飞,据说,发,不卡,弹幕,你,都,知道,么,不知,|112.60883634),(飞,> 知道,么,都,你,不知,据说,弹幕,不卡,发,|86.0976411055),
可见全是“飞”起决定作用的规则,这是因为奶奶嘴酱的弹幕只有飞。
就到这吧,码博客比码代码累:(
###项目地址 https://github.com/zuojie/MichineLearningCases/tree/master/NMF