机器学习实践:土豪们的最爱,为二手iphone5构建价格模型
11 Oct 2013
###背景&相关知识点
本case比较大杂烩,融合前面case中提到的一些算法,对商品价格进行模型构建。其中包括欧氏距离度量、模拟退火优化求解缩放向量、
高斯曲线法权值转换和KNN,新引入的概念方法有交叉校验和加权KNN等,个中还掺杂了笔者不顾代码可读性和代码效率,
欲拒还迎的大秀python技巧的卑劣行径(:P)。
###训练数据
首先,算法要求输入商品属性必须以数值表示,如果不是数值类型的属性,要想办法转为数值属性,还以房屋租金举个栗子:【地段, 房型,面积,装修情况,楼层,朝向】,其他其他都好说,地段这个属性不太好转换,假设简单粗暴把所有地段直接按序标号,用数值标号表示数值属性,则没考虑同一地段不同区域的价格相似性(比如整个北四环租金都完爆六环这种事实),这用上述简单的标记法体现不出来,所以需要人工标记,把属于同一地段的地名放到序列的相邻处,我是不会做这个的,累觉不爱有没有!再举一个。iphone5s/c刚发布,赶集网甚至为苹果搞了专卖专题页面,咱们就以iphone5系产品下手,来构建价格模型。初步设定属性包括:产品版本(iphone5/5s/5c), 内存(16G, 32G, 64G),颜色(黑色,白色,未说明)。这些属性都比较容易能很好得映射成数值属性,属性越少,越方便我们对价格模型进行解读。
数据的获取:数据仍然从赶集网获得,直接在iphone5的一级分类目录下抓取帖子的标题和价格,
手机属性在清洗标题的过程中获得,清洗规则为,
- 去掉价格单位, 合并标题中所有空格
- 价格低于1000高于6000的过滤
- 过滤标题中出现仿字的帖子(高仿,精仿等)
- 将标题字母全部转小写,提取[iphone5,iphone5s,iphone5c, iphone 5, iphone 5s, iphone 5c, 苹果5, 苹果五代, 苹果五, 苹果5c, 苹果5s] 等名字作为特征,合并相似项后,分别用1,2,3表示iphone5,iphone5s,iphone5c,这里标号没有实际意义,只是转化成数值属性方便算法处理。如果提取不到名字信息,按照iphone5处理
- 提取颜色信息,黑色为1,白色为2,没有默认3(可以理解为用户1喜欢黑色,用户2喜欢白色,用户3不在乎颜色,这是三种用户类型, 对应着三种不同的定价态度)
- 提取闪存大小,直接用作数值属性不再转化。如果没有闪存信息,数据忽略。
- 目测二手国行港版价格上并无差别,因此国行/港行属性忽略
原始数据共2600多条,格式如下:
 经过上述清洗规则,剩下1000多条,数据格式如下:
经过上述清洗规则,剩下1000多条,数据格式如下:
 上述分类属性向数值属性转化的过程中,存在一个问题,就是不同属性对价格的决定作用是不同的,而我们显然忽略了这一点,比如iphone的型号作用大于内存的作用,内存作用大于颜色作用。
但是我们把内存简单用1,2,3标注,内存用16,32,64标注,这样内存的数量级大于手机型号,导致计算不同帖子的向量距离(不同手机的相似度距离)时,
内存的差值会大幅度抵消型号差值带来的作用。于是我们需要对数据进行缩放归一。既然我们已经知道了不同属性的重要性
,为什么我们不直接手动进行缩放呢,比如把型号扩大10倍,颜色不变,内存扩大0.5倍等等。之所以我们没有手工做这个工作,是为了模拟现实中我们很多情况可能不知道不同属性对最终价格的影响重要程度。
所以我们借助模拟退火来来自动寻找最优缩放因子,由于这个过程较为耗时,所以可以跑一次然后结果落地到硬盘或者cache,后续直接取来用即可。
我这里优化算法跑出的缩放因子为[6, 1, 1], 虽然突出了型号的重要性,但是颜色和内存没有区分开,如果这里内存是0.5就好了。粗略猜测原因是模拟退货算法搜索解时是取的整型值,所以没有找到0.5这样的解。由于跑一次时间消耗太大,就没有修改模拟退火的实现重新求解。另外还有一点,原始的模拟退火虽然通过一定的概率再接受更差的解,从而避免陷入局部最优解,但是在实际运行过程中发现很多情况下找到的解还不是全局最优解,因为不同概率接受次优解的过程很可能跳过了最优解。于是对原始算法稍作修改,每次更改最优解时,用另一个单独变量x记录每次的最优解,相当于在每次迭代过程中都保留出现的最优解, 结合模拟退火的本质,我们既防止暴力搜索陷入局部最优,又防止模拟退火过程中跳过全局最右。这样最后使用的是这个x作为我们最终的解。
###算法流程
有了训练数据,当需要预测一个二手iphone5的售价时,我们假设有一部16G的iphone5需要估价,其响应的属性向量为[1, 3, 16]其中颜色没有指定,用3表示。我们把这个iphone5的属性向量和训练数据经过缩放因子作用后传给knn算法,knn算法首先会取得当前待预测手机和训练集中其他手机的相似度(欧几里得距离),然后取出Top k,对这些邻居价格求平均,即为预测价格。普通的KNN方法没有考虑不同邻居对价格影响的重要性不同,比如更相似的价格更具有参考价值。如果想克服这个缺点,可以使用加权knn算法,加权knn算法考虑了距离远近对价格影响的相关性,经过高斯算法把距离转化成对价格影响度的权值,我们计算最终价格时,分别将不同距离的邻居价格乘以其权值即可, 上述待预测的手机价格由knn给出的结果为3900。本案例由于数据属性很相近,所以加权knn和knn计算结果基本一致,不再分别讨论。
knn算法效果如何,可以根据交叉验证来判断,就是随机将训练数据分成训练组和测试组,判断其误差累积。第一步我们是直接问询算法获得了最终的预测值,但是更好的方式时把合理的价格区间展现给用户。
###可视化预测结果
生活中,更直观的估价方式为当我想转手我的iphone时,会首先参考很多同款型号配置的机器(邻居)的定价,然后决定最终价格。
换句话说,用户更希望看到同款机器价格分布的区间,我们可以借助概率分布图来展现指定配置的iphone在不同价格区间的概率分布。
2种方法如下:
上述分类属性向数值属性转化的过程中,存在一个问题,就是不同属性对价格的决定作用是不同的,而我们显然忽略了这一点,比如iphone的型号作用大于内存的作用,内存作用大于颜色作用。
但是我们把内存简单用1,2,3标注,内存用16,32,64标注,这样内存的数量级大于手机型号,导致计算不同帖子的向量距离(不同手机的相似度距离)时,
内存的差值会大幅度抵消型号差值带来的作用。于是我们需要对数据进行缩放归一。既然我们已经知道了不同属性的重要性
,为什么我们不直接手动进行缩放呢,比如把型号扩大10倍,颜色不变,内存扩大0.5倍等等。之所以我们没有手工做这个工作,是为了模拟现实中我们很多情况可能不知道不同属性对最终价格的影响重要程度。
所以我们借助模拟退火来来自动寻找最优缩放因子,由于这个过程较为耗时,所以可以跑一次然后结果落地到硬盘或者cache,后续直接取来用即可。
我这里优化算法跑出的缩放因子为[6, 1, 1], 虽然突出了型号的重要性,但是颜色和内存没有区分开,如果这里内存是0.5就好了。粗略猜测原因是模拟退货算法搜索解时是取的整型值,所以没有找到0.5这样的解。由于跑一次时间消耗太大,就没有修改模拟退火的实现重新求解。另外还有一点,原始的模拟退火虽然通过一定的概率再接受更差的解,从而避免陷入局部最优解,但是在实际运行过程中发现很多情况下找到的解还不是全局最优解,因为不同概率接受次优解的过程很可能跳过了最优解。于是对原始算法稍作修改,每次更改最优解时,用另一个单独变量x记录每次的最优解,相当于在每次迭代过程中都保留出现的最优解, 结合模拟退火的本质,我们既防止暴力搜索陷入局部最优,又防止模拟退火过程中跳过全局最右。这样最后使用的是这个x作为我们最终的解。
###算法流程
有了训练数据,当需要预测一个二手iphone5的售价时,我们假设有一部16G的iphone5需要估价,其响应的属性向量为[1, 3, 16]其中颜色没有指定,用3表示。我们把这个iphone5的属性向量和训练数据经过缩放因子作用后传给knn算法,knn算法首先会取得当前待预测手机和训练集中其他手机的相似度(欧几里得距离),然后取出Top k,对这些邻居价格求平均,即为预测价格。普通的KNN方法没有考虑不同邻居对价格影响的重要性不同,比如更相似的价格更具有参考价值。如果想克服这个缺点,可以使用加权knn算法,加权knn算法考虑了距离远近对价格影响的相关性,经过高斯算法把距离转化成对价格影响度的权值,我们计算最终价格时,分别将不同距离的邻居价格乘以其权值即可, 上述待预测的手机价格由knn给出的结果为3900。本案例由于数据属性很相近,所以加权knn和knn计算结果基本一致,不再分别讨论。
knn算法效果如何,可以根据交叉验证来判断,就是随机将训练数据分成训练组和测试组,判断其误差累积。第一步我们是直接问询算法获得了最终的预测值,但是更好的方式时把合理的价格区间展现给用户。
###可视化预测结果
生活中,更直观的估价方式为当我想转手我的iphone时,会首先参考很多同款型号配置的机器(邻居)的定价,然后决定最终价格。
换句话说,用户更希望看到同款机器价格分布的区间,我们可以借助概率分布图来展现指定配置的iphone在不同价格区间的概率分布。
2种方法如下:
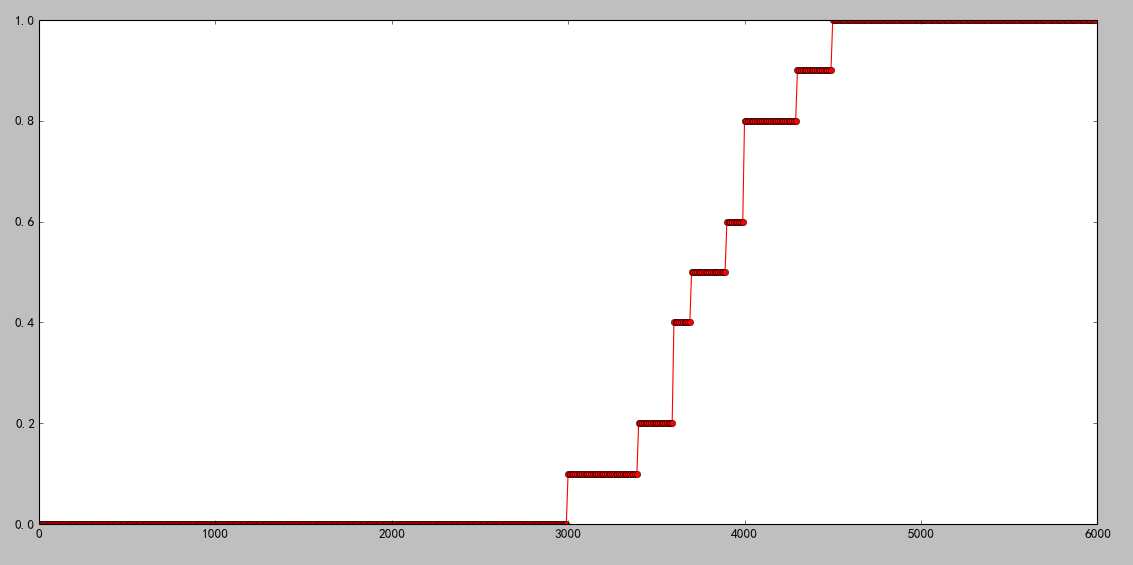
- 首先获取训练数据中定价的最大值和最小值,然后计算以最小值为起始点,最大值为重点的累计概率分布,当然也可以选择以0为起始点。由于累计概率分布靠后的价格概率值是前边概率值的累加,所以最终一定会等于1,针对我们要预测的iphone5价格概率累计分布图为:
- 另一种分布图为价格概率分布图,直观给出每种价格的概率值(通过微积分的思想计算,比如定价为x的占比,我们计算的是x到x+0.1的价格区间占总价格区间的比例),如下图所示:
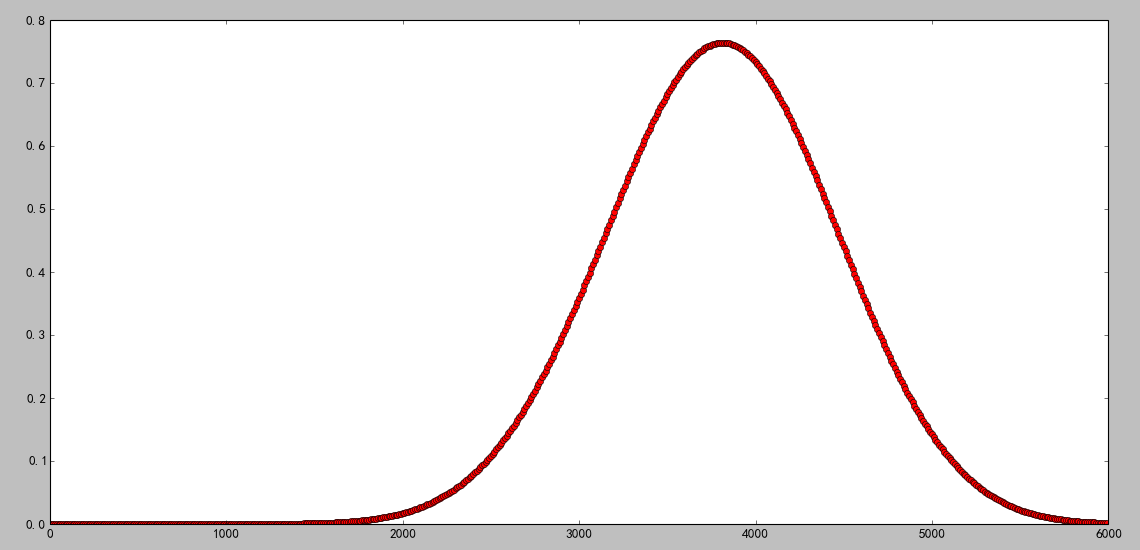
由数据可知,3000到4500之间的价格密度是最大的,也就是说一部二手iphone5的定价大部分都是落在了这个区间里。
###项目地址 https://github.com/zuojie/MichineLearningCases/tree/master/PriceModel