机器学习实践:赶集网数据大搜罗,窥探帝都房屋租金价格走势
07 Oct 2013
###背景&相关知识点
决策树模型是模拟人的简单逻辑思维过程(即决策一件事情时,只看每一步的主要因素,不考虑各种旁支条件)的一种模型,当一个人去决策一件事情的时候,会考虑各种情况最终给出结果策略。如下:
顾客:老板,我要卖房子
某中介:说说房子的情况吧
顾客:大一居;01年的房子;天安门那边;60平;没怎么装修;朝南
某中介:300w
以上,老板无形中在大脑中建立一棵决策树(诚然,中介老板是不大可能知道“决策树”这种听起来逼格很高的东西的,但是不妨碍人家使用),根据顾客提供的条件给出了最终的定价。决策树大概是这样的:
几居?如果是1居,则大概x万,2居,大概y万,3居,大概z万;哪一年的?如果2000年前的,则m万,2000年后的,则n万。。。
我们这里说的决策树算法就是对上述过程的模拟,并用一棵树形数据结构表达。
同样是上述例子,
- 首先,以几居作为第一个分支的节点,如果1居,则划分到右侧分支,否则划分到左侧分支;
- 然后对左右分支重新寻找分界点,假设以房子的年份作为新的分界点,根据不同年份将数据继续拆分成左右分支;
- 递归重复上述过程,直到数据不可再分为止。
决策时算法的核心除了最后生成一棵决策树方便决策者查看,对数据作解释之外,另一个关键的地方就是如何决定在每次分支时的分支条件,主要有3种算法:ID3和C4.5以及CART。
本项目采用了CART(分类回归决策树)算法,对ID3和C4.5(C4.5只是对ID3的一种改进算法)感兴趣的话请自行查阅相关资料。
CART算法在选择用哪个条件作为分支点的过程如下:
- 我们用熵来表示一个数据集的混乱程度,这里相当于前面几篇文章提到的惩罚函数,主要是用来度量数据按照某个条件拆分前后的熵值,据此 决定是否采用这个条件作为拆分点。拆分前后的熵的差值叫做信息增益(当前熵与2个拆分后的新数据集的加权平均之后的熵的差值),属于信息论范畴的感念,我们选择的便是信息增益最大的拆分点。 当然,熵只是其中一种度量数据集合的混乱程度。别的还有基尼不纯度,方差等。需要根据不同类型(分类型数据/数值型数据等)的数据集合来选择不同度量方式, 由于价格预测是属于数值型的数据,所以本项目采用的是方差。其他应用比如预测注册用户是真实用户还是机器人这种类别判断,一般会选择基尼不纯度和熵来度量数据混杂度。
- 每一步需要选择分支条件时,会对所有的条件进行拆分尝试,对比拆分前后的信息增益(嗅到一股低效的感觉),最后选择增益最大的条件作为分支,如果出现平局,随机选一个 就好。
- 递归进行,最终会生成一棵决策树。
由于本系列文章主要针对应用,如果想深入相关算法原理,需读者另行查阅相关资料(入门推荐《集体智慧编程》)。
应用以上算法,我们使用赶集网北京地区的房屋租赁数据做测试,赶集网每天关于租房的信息帖子大概有300页左右,每页80条左右帖子,就是说
每天租房相关的发帖量大概在300 * 80 = 24000条,这里不考虑中介重复发帖的情况。数据爬取的过程发现这些数据有如下特点:
每条标准的租房帖子会包括和房子相关的信息有:房间数量(x室y厅z卫)、房子大小(平方米)、装修情况、房子所在楼层,房子朝向、发帖日期、
租金。其中会有数据缺失的情况,主要集中在装修情况和房子朝向的描述缺失。经过一系列的数据清洗,最终得到干净整洁的数据有11864条数据。
这些数据缺失行用None代替,房子租金在最后一列(决策树算法库要求输入格式为预测结果列在最后一列)。如下所示:
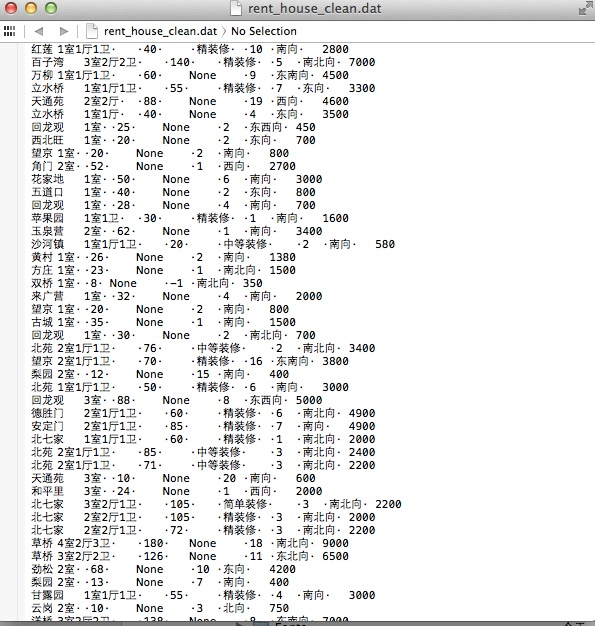
画图继续使用PIL,但是碰到了瓶颈,PIL限制图片生成大小在65500像素之内。意味着这些数据不能全部用来训练生成决策树,其实即使没有PIL的这个限制,
由于决策树算法本身的低效性,当使用1w条数据全部拿来训练算法也要运行很久的。所以这里本着验证学习理论的原则,咱们分别使用100,500
,800,1000,3000,5000条抽样数据分别运行决策树算法。并对数据[“安定门”, “2室1厅1卫”, 85, “精装修”, 7, “南向”]进行测试,这条测试数据的实际结果定价为4900元,
我们看一下不同训练集时的预测效果。
结果如下:
| 训练数据数量 | 基尼不纯度 | 熵 | 决策树 | 预测结果(元) |
| 100 | 0.969819300269 | 5.31698570091 | 原始,剪枝 | 4900 |
| 500 | 0.982293931842 | 6.12294035457 | 原始,剪枝 | 3350 |
| 800 | 0.983666146355 | 6.26365651442 | 原始,剪枝 | 4600 |
| 1000 | 0.984257034833 | 6.37351092431 | 原始,剪枝 | 5499 |
| 3000 | 0.984563033927 | 6.4751437962 | 原始,剪枝 | 600 |
备注:最终的预测结果由决策树给出的形式实际为A(x),B(y)等,即采用A价格的有x个,B价格的有y个,这是可以理解的,
通常给房屋定价时会参考别人都是怎么定的,某些价位有多少人采用。这里为了方便展示,直接取了采用人数最多的价位作为预测价格。另外,3000的
图请谨慎打开,忒大
ps:3.17G的磁盘剩余空间,使用windows照片查看器查看一副14MB的图片,竟然用掉2.6GB左右的硬盘空间,这。。。
当数据量过大时,生成的决策树可读性很差,这里只贴出数据量为100时生成的决策树(如嫌图小请在图上右键新窗口打开图片放大观看),结合上述表格中的信息进行一些解读。
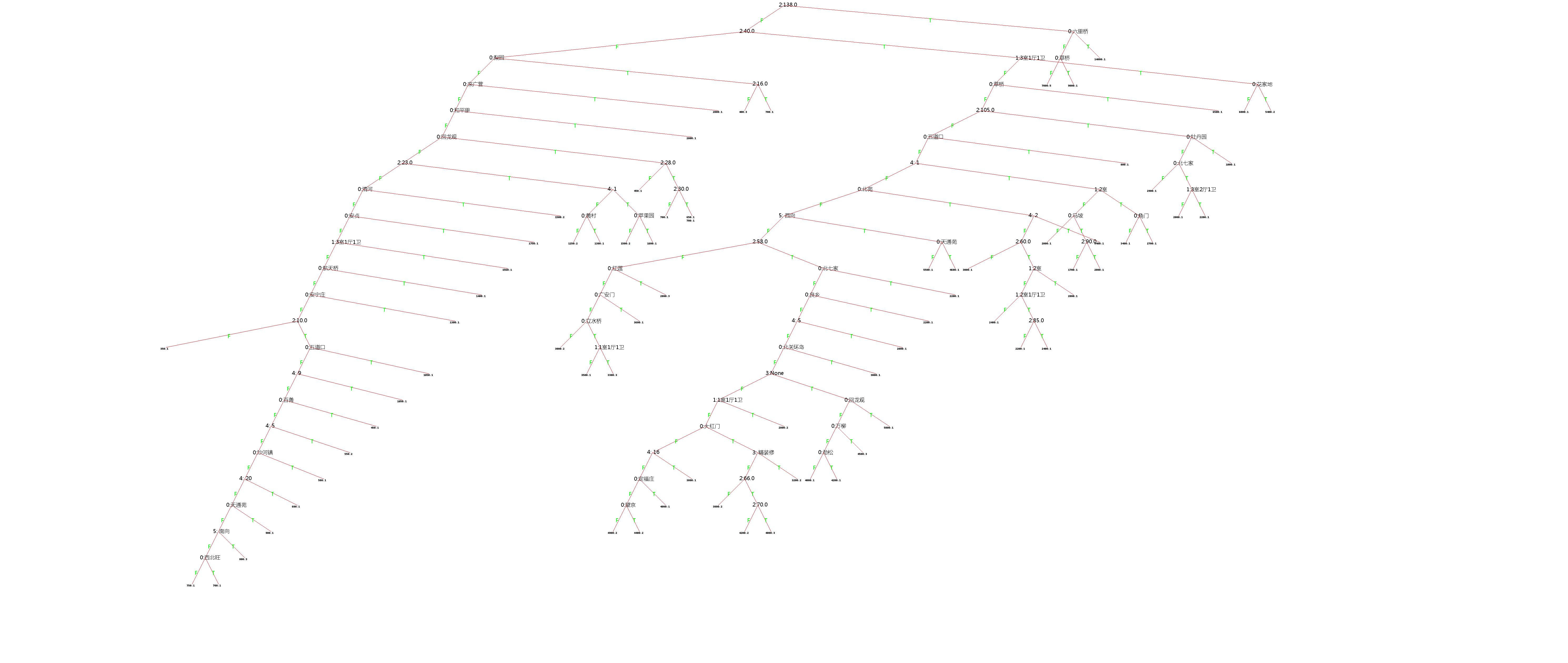 决策树中,首先根节点根据第二列(下标从0开始)数据房子面积对数据进行了第一步拆分,意味着在这100条训练集里,房子面积对最终的租金价格
起着决定性的作用。纳尼,难道地段不重要?地段自然重要,但是由于数据集采样的不均衡,导致第一重要的因素不是地段也可以理解,但是
由于现实中地段真的很重要,所以无论数据集如何采样,只要达到一定了的规模,决策树中肯定会出现大量的以第0个字段“地段”为分支条件的节点,
根据上图,是符合这个规律的。对于更大的数据量,大家可以参考表格中的决策树图片, 是都符合这个规律的。
决策树中,首先根节点根据第二列(下标从0开始)数据房子面积对数据进行了第一步拆分,意味着在这100条训练集里,房子面积对最终的租金价格
起着决定性的作用。纳尼,难道地段不重要?地段自然重要,但是由于数据集采样的不均衡,导致第一重要的因素不是地段也可以理解,但是
由于现实中地段真的很重要,所以无论数据集如何采样,只要达到一定了的规模,决策树中肯定会出现大量的以第0个字段“地段”为分支条件的节点,
根据上图,是符合这个规律的。对于更大的数据量,大家可以参考表格中的决策树图片, 是都符合这个规律的。
其实,看到这里大家已经发现了决策树在应对稍微上点规模的数据量时的捉襟见肘,不进行一番痛彻心骨的优化显然是上不了生产环境的,下一篇博客会讲述其他更好的构建价格模型的算法。
###项目地址 https://github.com/zuojie/MichineLearningCases/tree/master/DecisionTree